Chapter 7: Beyond Adjustment: The Conquest of Mount Intervention
He whose actions exceed his theory, his theory shall endure.
-RABBI HANINA BEN DOSA (FIRST CENTURY AD)
IN this chapter we finally make our bold ascent onto the second level of the Ladder of Causation, the level of intervention-the holy grail of causal thinking from antiquity to the present day. This level is involved in the struggle to predict the effects of actions and policies that haven't been tried yet, ranging from medical treatments to social programs, from economic policies to personal choices. Confounding was the primary obstacle that caused us to confuse seeing with doing. Having removed this obstacle with the tools of 'path blocking' and the back-door criterion, we can now map the routes up Mount Intervention with systematic precision. For the novice climber, the safest routes up the mountain are the back-door adjustment and its various cousins, some going under the rubric of 'front-door adjustment' and some under 'instrumental variables.'
But these routes may not be available in all cases, so for the experienced climber this chapter describes a 'universal mapping tool' called the do -calculus, which allows the researcher to explore and plot all possible routes up Mount Intervention, no matter how twisty. Once a route has been mapped, and the ropes and carabiners and pitons are in place, our assault on the mountain will assuredly result in a successful conquest!
THE SIMPLEST ROUTE: THE BACK-DOOR ADJUSTMENT FORMULA
For many researchers, the most (perhaps only) familiar method of predicting the effect of an intervention is to 'control' for confounders using the adjustment formula. This is the method to use if you are confident that you have data on a sufficient set of variables (called deconfounders) to block all the back-door paths between the intervention and the outcome. To do this, we measure the average causal effect of an intervention by first estimating its effect at each 'level,' or stratum, of the deconfounder. We then compute a weighted average of those strata, where each stratum is weighted according to its prevalence in the population. If, for example, the deconfounder is gender, we first estimate the causal effect for males and females. Then we average the two, if the population is (as usual) half male and half female. If the proportions are different-say, two-thirds male and one-third female-then to estimate the average causal effect we would take a correspondingly weighted average.
The role that the back-door criterion plays in this procedure is to guarantee that the causal effect in each stratum of the deconfounder is none other than the observed trend in this stratum. So the causal effect can be estimated stratum by stratum from the data. Absent the back-door criterion, researchers have no guarantee that any adjustment is legitimate.
The fictitious drug example in Chapter 6 was the simplest situation possible: one treatment variable (Drug D ), one outcome (Heart Attack), one confounder (Gender), and all three variables are binary. The example shows how we take a weighted average of the conditional probabilities P heart ( attack | drug ) in each gender stratum. But the procedure described above can be adapted easily to handle more complicated situations, including multiple (de)confounders and multiple strata.
However, in many cases, the variables X Y , , or Z take numerical valuesfor example, income or height or birth weight. We saw this in our visual example of Simpson's paradox. Because the variable could take (at least, for all practical purposes) infinite possible values, we cannot make a table listing all the possibilities, as we did in Chapter 6.
An obvious remedy is to separate the numerical values into a finite and manageable number of categories. There is nothing in principle wrong with this option, but the choice of categories is a bit arbitrary. Worse, if we have more than a handful of adjusted variables, we get an exponential blowup in
the number of categories. This will make the procedure computationally prohibitive; worse yet, many of the strata will end up devoid of samples and thus incapable of providing any probability estimates whatsoever.
Statisticians have devised ingenious methods for handling this 'curse of dimensionality' problem. Most involve some sort of extrapolation, whereby a smooth function is fitted to the data and used to fill in the holes created by the empty strata.
The most widely used smoothing function is of course a linear approximation, which served as the workhorse of most quantitative work in the social and behavioral sciences in the twentieth century. We have seen how Sewall Wright embedded his path diagrams into the context of linear equations, and we noted there one computational advantage of this embedding: every causal effect can be represented by a single number (the path coefficient). A second and no less important advantage of linear approximations is the astonishing simplicity of computing the adjustment formula.
We have previously seen Francis Galton's invention of a regression line, which takes a cloud of data points and interpolates the best-fitting line through that cloud. In the case of one treatment variable ( X ) and one outcome variable ( Y ), the equation of the regression line will look like this: Y = aX + b . The parameter a (often denoted by r YX , the regression coefficient of Y on X ) tells us the average observed trend: a one-unit increase of X will, on average, produce an a -unit increase in Y . If there are no confounders of Y and X , then we can use this as our estimate of an intervention to increase X by one unit.
But what if there is a confounder, Z ? In this case, the correlation coefficient r YX will not give us the average causal effect; it only gives us the average observed trend. That was the case in Wright's problem of the guinea pig birth weights, discussed in Chapter 2, where the apparent benefit (5.66 grams) of an extra day's gestation was biased because it was confounded with the effect of a smaller litter size. But there is still a way out: by plotting all three variables together, with each value of ( X Y Z , , ) describing one point in space. In this case, the data will form a cloud of points in XYZ -space. The analogue of a regression line is a regression plane, which has an equation that looks like Y = aX + bZ + c . We can easily compute a b , , c from the data. Here something wonderful happens, which Galton did not realize but Karl Pearson and George Udny Yule certainly did. The coefficient a gives us the regression coefficient of Y on X already adjusted for Z . (It is called a partial regression coefficient and written r YX.Z .)
Thus we can skip the cumbersome procedure of regressing Y on X for each level of Z and computing the weighted average of the regression coefficients. Nature already does all the averaging for us! We need only compute the plane that best fits the data. A statistical package will do it in no time. The coefficient a in the equation of that plane, Y = aX + bZ + c , will automatically adjust the observed trend of Y on X to account for the confounder Z . If Z is the only confounder, then a is the average causal effect of X on Y . A truly miraculous simplification!
You can easily extend the procedure to deal with multiple variables as well. If the set of variables Z should happen to satisfy the back-door condition, then the coefficient of X in the regression equation, a , will be none other than the average causal effect of X on Y .
For this reason generations of researchers came to believe that adjusted (or partial) regression coefficients are somehow endowed with causal information that unadjusted regression coefficients lack. Nothing could be further from the truth. Regression coefficients, whether adjusted or not, are only statistical trends, conveying no causal information in themselves. r YX.Z represents the causal effect of X on Y , whereas r YX does not, exclusively because we have a diagram showing Z as a confounder of X and Y .
In short, sometimes a regression coefficient represents a causal effect, and sometimes it does not-and you can't rely on the data alone to tell you the difference. Two additional ingredients are required to endow r YX.Z with causal legitimacy. First, the path diagram should represent a plausible picture of reality, and second, the adjusted variable(s) Z should satisfy the back-door criterion.
That is why it was so crucial that Sewall Wright distinguished path coefficients (which represent causal effects) from regression coefficients (which represent trends of data points). Path coefficients are fundamentally different from regression coefficients, although they can often be computed from the latter. Wright failed to realize, however, as did all path analysts and econometricians after him, that his computations were unnecessarily complicated. He could have gotten the path coefficients from partial correlation coefficients, if only he had known that the proper set of adjusting variables can be identified, by inspection, from the path diagram itself.
Keep in mind also that the regression-based adjustment works only for linear models, which involve a major modeling assumption. With linear models, we lose the ability to model nonlinear interactions, such as when the effect of X on Y depends on the level of Z . The back-door adjustment, on the
other hand, still works fine even when we have no idea what functions are behind the arrows in the diagrams. But in this so-called nonparametric case, we need to employ other extrapolation methods to deal with the curse of dimensionality.
To sum up, the back-door adjustment formula and the back-door criterion are like the front and back of a coin. The back-door criterion tells us which sets of variables we can use to deconfound our data. The adjustment formula actually does the deconfounding. In the simplest case of linear regression, partial regression coefficients perform the back-door adjustment implicitly. In the nonparametric case, we must do the adjustment explicitly, either using the back-door adjustment formula directly on the data or on some extrapolated version of it.
You might think that our assault on Mount Intervention would end there with complete success. Unfortunately, though, adjustment does not work at all if there is a back-door path we cannot block because we don't have the requisite data. Yet we can still use certain tricks even in this situation. I will tell you about one of my favorite methods next, called the front-door adjustment. Even though it was published more than twenty years ago, only a handful of researchers have taken advantage of this shortcut up Mount Intervention, and I am convinced that its full potential remains untapped.
THE FRONT-DOOR CRITERION
The debate over the causal effect of smoking occurred at least two generations too early for causal diagrams to make any contribution. We have already seen how Cornfield's inequality helped persuade researchers that the smoking gene, or 'constitutional hypothesis,' was highly implausible. But a more radical approach, using causal diagrams, could have shed more light on the hypothetical gene and possibly eliminated it from further consideration.
Suppose that researchers had measured the tar deposits in smokers' lungs. Even in the 1950s, the formation of tar deposits was suspected as one of the possible intermediate stages in the development of lung cancer. Suppose also that, just like the Surgeon General's committee, we want to rule out R. A. Fisher's hypothesis that a smoking gene confounds smoking behavior and lung cancer. We might then arrive at the causal diagram in Figure 7.1.
Figure 7.1 incorporates two very important assumptions, which we'll suppose are valid for the purpose of our example. The first assumption is that
the smoking gene has no effect on the formation of tar deposits, which are exclusively due to the physical action of cigarette smoke. (This assumption is indicated by the lack of an arrow between Smoking Gene and Tar; it does not rule out, however, random factors unrelated to Smoking Gene.) The second significant assumption is that Smoking leads to Cancer only through the accumulation of tar deposits. Thus we assume that no direct arrow points from Smoking to Cancer, and there are no other indirect pathways.
FIGURE 7.1. Hypothetical causal diagram for smoking and cancer, suitable for front-
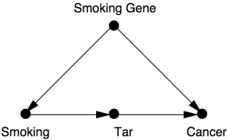
door adjustment.
Suppose we are doing an observational study and have collected data on Smoking, Tar, and Cancer for each of the participants. Unfortunately, we cannot collect data on the Smoking Gene because we do not know whether such a gene exists. Lacking data on the confounding variable, we cannot block the back-door path Smoking Smoking Gene Cancer. Thus we cannot use back-door adjustment to control for the effect of the confounder.
So we must look for another way. Instead of going in the back door, we can go in the front door! In this case, the front door is the direct causal path Smoking Tar Cancer, for which we do have data on all three variables. Intuitively, the reasoning is as follows. First, we can estimate the average causal effect of Smoking on Tar, because there is no unblocked back-door path from Smoking to Cancer, as the Smoking Smoking Gene Cancer Tar path is already blocked by the collider at Cancer. Because it is blocked already, we don't even need back-door adjustment. We can simply observe P tar ( | smoking ) and P tar ( | no smoking ), and the difference between them will be the average causal effect of Smoking on Tar.
Likewise, the diagram allows us to estimate the average causal effect of Tar on Cancer. To do this we can block the back-door path from Tar to Cancer, Tar Smoking Smoking Gene Cancer, by adjusting for Smoking. Our lessons from Chapter 4 come in handy: we only need data on a sufficient set of deconfounders (i.e., Smoking). Then the back-door adjustment formula will give us P cancer ( | do tar ( )) and P cancer ( | do no ( tar )). The difference between these is the average causal effect of Tar on Cancer.
Now we know the average increase in the likelihood of tar deposits due to smoking and the average increase of cancer due to tar deposits. Can we combine these somehow to obtain the average increase in cancer due to smoking? Yes, we can. The reasoning goes as follows. Cancer can come about in two ways: in the presence of Tar or in the absence of Tar. If we force a person to smoke, then the probabilities of these two states are P tar ( | do smoking ( )) and P no tar ( | do no smoking ( )), respectively. If a Tar state evolves, the likelihood of causing Cancer is P cancer ( | do tar ( )). If, on the other hand, a No-Tar state evolves, then it would result in a Cancer likelihood of P cancer ( | do no tar ( )). We can weight the two scenarios by their respective probabilities under do smoking ( ) and in this way compute the total probability of cancer due to smoking. The same argument holds if we prevent a person from smoking, do no smoking ( ). The difference between the two gives us the average causal effect on cancer of smoking versus not smoking.
As I have just explained, we can estimate each of the do -probabilities discussed from the data. That is, we can write them mathematically in terms of probabilities that do not involve the do -operator. In this way, mathematics does for us what ten years of debate and congressional testimony could not: quantify the causal effect of smoking on cancer-provided our assumptions hold, of course.
The process I have just described, expressing P cancer ( | do ( smoking )) in terms of do -free probabilities, is called the front-door adjustment. It differs from the back-door adjustment in that we adjust for two variables (Smoking and Tar) instead of one, and these variables lie on the front-door path from Smoking to Cancer rather than the back-door path. For those readers who 'speak mathematics,' I can't resist showing you the formula (Equation 7.1), which cannot be found in ordinary statistics textbooks. Here X stands for Smoking, Y stands for Cancer, Z stands for Tar, and U (which is conspicuously absent from the formula) stands for the unobservable variable, the Smoking Gene.
$$P Y ( | do X ( )) = ∑ z P Z ( = z , X ) ∑ x P Y ( | X = x , Z = z ) P X ( = x ) (7.1)$$ Readers with an appetite for mathematics might find it interesting to compare this to the formula for the back-door adjustment, which looks like Equation 7.2.
$$P Y ( | do X ( )) = ∑ z P Y ( | X Z , = z ) P Z ( = z ) (7.2)$$ Even for readers who do not speak mathematics, we can make several interesting points about Equation 7.1. First and most important, you don't see
U (the Smoking Gene) anywhere. This was the whole point. We have successfully deconfounded U even without possessing any data on it. Any statistician of Fisher's generation would have seen this as an utter miracle. Second, way back in the Introduction I talked about an estimand as a recipe for computing the quantity of interest in a query. Equations 7.1 and 7.2 are the most complicated and interesting estimands that I will show you in this book. The left-hand side represents the query 'What is the effect of X on Y ?' The right-hand side is the estimand, a recipe for answering the query. Note that the estimand contains no do 's, only see 's, represented by the vertical bars, and this means it can be estimated from data.
At this point, I'm sure that some readers are wondering how close this fictional scenario is to reality. Could the smoking-cancer controversy have been resolved by one observational study and one causal diagram? If we assume that Figure 7.1 accurately reflects the causal mechanism for cancer, the answer is absolutely yes. However, we now need to discuss whether our assumptions are valid in the real world.
David Freedman, a longtime friend and a Berkeley statistician, took me to task over this issue. He argued that the model in Figure 7.1 is unrealistic in three ways. First, if there is a smoking gene, it might also affect how the body gets rid of foreign matter in the lungs, so that people with the gene are more vulnerable to the formation of tar deposits and people without it are more resistant. Therefore, he would draw an arrow from Smoking Gene to Tar, and in that case the front-door formula would be invalid.
Freedman also considered it unlikely that Smoking affects Cancer only through Tar. Certainly other mechanisms could be imagined; perhaps smoking produces chronic inflammation that leads to cancer. Finally, he said, tar deposits in a living person's lungs cannot be measured with sufficient accuracy anyway-so an observational study such as the one I have proposed cannot be conducted in the real world.
I have no quarrel with Freedman's criticism in this particular example. I am not a cancer specialist, and I would always have to defer to the expert opinion on whether such a diagram represents the real-world processes accurately. In fact, one of the major accomplishments of causal diagrams is to make the assumptions transparent so that they can be discussed and debated by experts and policy makers.
However, the point of my example was not to propose a new mechanism for the effect of smoking but to demonstrate how mathematics, given the right situation, can eliminate the effect of confounders even without data on the
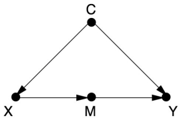
confounder. And the situation can be clearly recognized. Anytime the causal effect of X on Y is confounded by one set of variables ( C ) and mediated by another ( M ) (see Figure 7.2), and, furthermore, the mediating variables are shielded from the effects of C , then you can estimate X 's effect from observational data. Once scientists are made aware of this fact, they should seek shielded mediators whenever they face incurable confounders. As Louis Pasteur said, 'Fortune favors the prepared mind.'
Fortunately, the virtues of front-door adjustment have not remained completely unappreciated. In 2014, Adam Glynn and Konstantin Kashin, both political scientists at Harvard (Glynn subsequently moved to Emory University), wrote a prize-winning paper that should be required reading for all quantitative social scientists. They applied the new method to a data set well scrutinized by social scientists, called the Job Training Partnership Act (JTPA) Study, conducted from 1987 to 1989. As a result of the 1982 JTPA, the Department of Labor created a job-training program that, among other services, provided participants with occupational skills, job-search skills, and work experience. It collected data on people who applied for the program, people who actually used the services, and their earnings over the subsequent eighteen months. Notably, the study included both a randomized controlled trial (RCT), where people were randomly assigned to receive services or not, and an observational study, in which people could choose for themselves.
FIGURE 7.2. The basic setup for the front-door criterion.
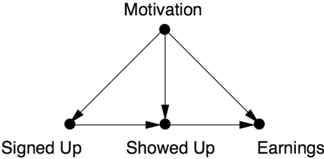
Glynn and Kashin did not draw a causal diagram, but from their description of the study, I would draw it as shown in Figure 7.3. The variable Signed Up records whether a person did or did not register for the program; the variable Showed Up records whether the enrollee did or did not actually use the services. Obviously the program can only affect earnings if the user actually shows up, so the absence of a direct arrow from Signed Up to Earnings is easy to justify.
Glynn and Kashin refrain from specifying the nature of the confounders, but I have summed them up as Motivation. Clearly, a person who is highly motivated to increase his or her earnings is more likely to sign up. That person is also more likely to earn more after eighteen months, regardless of whether he or she shows up. The goal of the study is, of course, to disentangle
the effect of this confounding factor and find out just how much the services themselves are helping.
FIGURE 7.3. Causal diagram for the JTPA Study.
Comparing Figure 7.2 to Figure 7.3, we can see that the front-door criterion would apply if there were no arrow from Motivation to Showed Up, the 'shielding' I mentioned earlier. In many cases we could justify the absence of that arrow. For example, if the services were only offered by appointment and people only missed their appointments because of chance events unrelated to Motivation (a bus strike, a sprained ankle, etc.), then we could erase that arrow and use the front-door criterion.
Under the actual circumstances of the study, where the services were available all the time, such an argument is hard to make. However-and this is where things get really interesting-Glynn and Kashin tested out the frontdoor criterion anyway. We might think of this as a sensitivity test. If we suspect that the middle arrow is weak, then the bias introduced by treating it as absent may be very small. Judging from their results, that was the case.
By making certain reasonable assumptions, Glynn and Kashin derived inequalities saying whether the adjustment was likely to be too high or too low and by how much. Finally, they compared the front-door predictions and back-door predictions to the results from the randomized controlled experiment that was run at the same time. The results were impressive. The estimates from the back-door criterion (controlling for known confounders like Age, Race, and Site) were wildly incorrect, differing from the experimental benchmarks by hundreds or thousands of dollars. This is exactly what you would expect to see if there is an unobserved confounder, such as Motivation. The back-door criterion cannot adjust for it.
On the other hand, the front-door estimates succeeded in removing almost all of the Motivation effect. For males, the front-door estimates were well within the experimental error of the randomized controlled trial, even with the small positive bias that Glynn and Kashin predicted. For females, the results were even better: The front-door estimates matched the experimental benchmark almost perfectly, with no apparent bias. Glynn and Kashin's work
gives both empirical and methodological proof that as long as the effect of C on M (in Figure 7.2) is weak, front-door adjustment can give a reasonably good estimate of the effect of X on Y . It is much better than not controlling for C .
Glynn and Kashin's results show why the front-door adjustment is such a powerful tool: it allows us to control for confounders that we cannot observe (like Motivation), including those that we can't even name. RCTs are considered the 'gold standard' of causal effect estimation for exactly the same reason. Because front-door estimates do the same thing, with the additional virtue of observing people's behavior in their own natural habitat instead of a laboratory, I would not be surprised if this method eventually becomes a serious competitor to randomized controlled trials.
THE DO -CALCULUS, OR MIND OVER MATTER
In both the front- and back-door adjustment formulas, the ultimate goal is to calculate the effect of an intervention, P Y ( | do X ( )), in terms of data such as P Y ( | X A B Z , , , ,…) that do not involve a do -operator. If we are completely successful at eliminating the do 's, then we can use observational data to estimate the causal effect, allowing us to leap from rung one to rung two of the Ladder of Causation.
The fact that we were successful in these two cases (front- and back-door) immediately raises the question of whether there are other doors through which we can eliminate all the do 's. Thinking more generally, we can ask whether there is some way to decide in advance if a given causal model lends itself to such an elimination procedure. If so, we can apply the procedure and find ourselves in possession of the causal effect, without having to lift a finger to intervene. Otherwise, we would at least know that the assumptions imbedded in the model are not sufficient to uncover the causal effect from observational data, and no matter how clever we are, there is no escape from running an interventional experiment of some kind.
The prospect of making these determinations by purely mathematical means should dazzle anybody who understands the cost and difficulty of running randomized controlled trials, even when they are physically feasible and legally permissible. The idea dazzled me, too, in the early 1990s, not as an experimenter but as a computer scientist and part-time philosopher. Surely one of the most exhilarating experiences you can have as a scientist is to sit at your desk and realize that you can finally figure out what is possible or
impossible in the real world-especially if the problem is important to society and has baffled those who have tried to solve it before you. I imagine this is how Hipparchus of Nicaea felt when he discovered he could figure out the height of a pyramid from its shadow on the ground, without actually climbing the pyramid. It was a clear victory of mind over matter.
Indeed, the approach I took was very much inspired by the ancient Greeks (including Hipparchus) and their invention of a formal logical system for geometry. At the center of the Greeks' logic, we find a set of axioms or selfevident truths, such as 'Between any two points one can draw one and only one line.' With the help of those axioms, the Greeks could construct complex statements, called theorems, whose truth is far from evident. Take, for instance, the statement that the sum of the angles in a triangle is 180 degrees (or two right angles), regardless of its size or shape. The truth of this statement is not self-evident by any means; yet the Pythagorean philosophers of the fifth century BC were able to prove its universal truth using those selfevident axioms as building blocks.
If you remember your high school geometry, even just the gist of it, you will recall that proofs of theorems invariably consist of auxiliary constructions: for example, drawing a line parallel to an edge of a triangle, marking certain angles as equal, drawing a circle with a given segment as its radius, and so on. These auxiliary constructions can be regarded as temporary mathematical sentences that make assertions (or claims) about properties of the figure drawn. Each new construction is licensed by the previous ones, as well as by the axioms of geometry and perhaps some already derived theorems. For example, drawing a line parallel to one edge of a triangle is licensed by Euclid's fifth axiom, that it is possible to draw one and only one parallel to a given line from a point outside that line. The act of drawing any of these auxiliary constructions is just a mechanical 'symbol manipulation' operation; it takes the sentence previously written (or picture previously drawn) and rewrites it in a new format, whenever the rewriting is licensed by the axioms. Euclid's greatness was to identify a short list of five elementary axioms, from which all other true geometric statements can be derived.
Now let us return to our central question of when a model can replace an experiment, or when a 'do' quantity can be reduced to a 'see' quantity. Inspired by the ancient Greek geometers, we want to reduce the problem to symbol manipulation and in this way wrest causality from Mount Olympus and make it available to the average researcher.
First, let us rephrase the task of finding the effect of X on Y using the
language of proofs, axioms, and auxiliary constructions, the language of Euclid and Pythagoras. We start with our target sentence, P Y ( | do X ( )). Our task will be complete if we can succeed in eliminating the do -operator from it, leaving only classical probability expressions, like P Y ( | X ) or P Y ( | X Z W , , ). We cannot, of course, manipulate our target expression at will; the operations must conform to what do X ( ) means as a physical intervention. Thus, we must pass the expression through a sequence of legitimate manipulations, each licensed by the axioms and the assumptions of our model. The manipulations should preserve the meaning of the manipulated expression, only changing the format it is written in. An example of a 'meaning preserving' transformation is the algebraic transformation that turns y = ax + b into ax = y -b . The relationship between x and y remains intact; only the format changes.
We are already familiar with some 'legitimate' transformations on do -expressions. For example, Rule 1 says when we observe a variable W that is irrelevant to Y (possibly conditional on other variables Z ), then the probability distribution of Y will not change. For example, in Chapter 3 we saw that the variable Fire is irrelevant to Alarm once we know the state of the mediator (Smoke). This assertion of irrelevance translates into a symbolic manipulation:
$$P Y ( | do X ( ), Z W , ) = P Y ( | do X ( ), Z )$$ The stated equation holds provided that the variable set Z blocks all the paths from W to Y after we have deleted all the arrows leading into X . In the example of Fire Smoke Alarm, we have W = Fire, Z = Smoke, Y = Alarm, and Z blocks all the paths from W to Y . (In this case we do not have a variable X .)
Another legitimate transformation is familiar to us from our back-door discussion. We know that if a set Z of variables blocks all back-door paths from X to Y , then conditional on Z , do X ( ) is equivalent to see X ( ). We can, therefore, write
$$P Y ( | do X ( ), Z ) = P Y ( | X Z , )$$ if Z satisfies the back-door criterion. We adopt this as Rule 2 of our axiomatic system. While this is perhaps less self-evident than Rule 1, in the simplest cases it is Hans Reichenbach's common-cause principle, amended so that we won't mistake colliders for confounders. In other words, we are saying that after we have controlled for a sufficient deconfounding set, any remaining correlation is a genuine causal effect.
Rule 3 is quite simple: it essentially says that we can remove do X ( ) from
P Y ( | do X ( )) in any case where there are no causal paths from X to Y . That is,
P Y ( | do X ( )) = P Y ( )
if there is no path from X to Y with only forward-directed arrows. We can paraphrase this rule is follows: if we do something that does not affect Y , then the probability distribution of Y will not change. Aside from being just as selfevident as Euclid's axioms, Rules 1 to 3 can also be proven mathematically using our arrow-deleting definition of the do -operator and basic laws of probability.
Note that Rules 1 and 2 include conditional probabilities involving auxiliary variables Z other than X and Y . These variables can be thought of as a context in which the probability is being computed. Sometimes the presence of this context itself licenses the transformation. Rule 3 may also have auxiliary variables, but I omitted them for simplicity.
Note that each rule has a simple syntactic interpretation. Rule 1 permits the addition or deletion of observations. Rule 2 permits the replacement of an intervention with an observation, or vice versa. Rule 3 permits the deletion or addition of interventions. All of these permits are issued under appropriate conditions, which have to be verified in any particular case from the causal diagram.
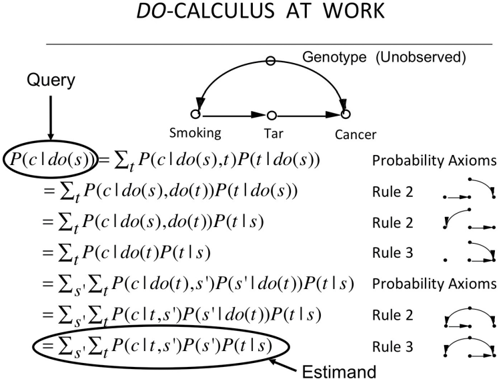
We are ready now to demonstrate how Rules 1 to 3 allow us to transform one formula into another until, if we are smart, we obtain an expression to our liking. Although it's a bit elaborate, I think that nothing can substitute for actually showing you how the front-door formula is derived using a successive application of the rules of do -calculus (Figure 7.4). You do not need to follow all the steps, but I am showing you the derivation to give you the flavor of do -calculus. We begin the journey with a target expression P Y ( | do X ( )). We introduce auxiliary variables and transform the target expression into a do -free expression that coincides, of course, with the front-door adjustment formula. Each step of the argument gets its license from the causal diagram that relates X Y , , and the auxiliary variables or, in several cases, from subdiagrams that have had arrows erased to account for interventions. These licenses are displayed on the right-hand side.
I feel a special attachment to the do -calculus. With these three humble rules I was able to derive the front-door formula. This was the first causal effect estimated by means other than control for confounders. I believed no one could do this without the do -calculus, so I presented it as a challenge in a statistics seminar at Berkeley in 1993 and even offered a $100 prize to anyone
who could solve it. Paul Holland, who attended the seminar, wrote that he had assigned the problem as a class project and would send me the solution when ripe. (Colleagues tell me that he eventually presented a long solution at a conference in 1995, and I may owe him $100 if I could only find his proof.) Economists James Heckman and Rodrigo Pinto made the next attempt to prove the front-door formula using 'standard tools' in 2015. They succeeded, albeit at the cost of eight pages of hard labor.
FIGURE 7.4. Derivation of the front-door adjustment formula from the rules of do -calculus.
In a restaurant the evening before the talk, I had written the proof (very much like the one in Figure 7.4) on a napkin for David Freedman. He wrote me later to say that he had lost the napkin. He could not reconstruct the argument and asked if I had kept a copy. The next day, Jamie Robins wrote to me from Harvard, saying that he had heard about the 'napkin problem' from Freedman, and he straightaway offered to fly to California to check the proof with me. I was thrilled to share with Robins the secrets of the do -calculus, and I believe that his trip to Los Angeles that year has been the key to his enthusiastic acceptance of causal diagrams. Through his and Sander Greenland's influence, diagrams have become a second language for epidemiologists. This explains why I am so fond of the 'napkin problem.'
The front-door adjustment formula was a delightful surprise and an indication that do -calculus had something important to offer. However, at this point I still wondered whether the three rules of do -calculus were enough. Was it possible that we had missed a fourth rule that would help us solve problems that are unsolvable with only three?
In 1994, when I first proposed the do -calculus, I selected these three rules
because they were sufficient in any case that I knew of. I had no idea whether, like Ariadne's thread, they would always lead me out of the maze, or I would someday encounter a maze of such fiendish complexity that I could not escape. Of course, I hoped for the best. I conjectured that whenever a causal effect is estimable from data, a sequence of steps using these three rules would eliminate the do -operator. But I could not prove it.
This type of problem has many precedents in mathematics and logic. The property is usually called 'completeness' in mathematical logic; an axiom system that is complete has the property that the axioms suffice to derive every true statement in that language. Some very good axiom systems are incomplete: for instance, Philip Dawid's axioms describing conditional independence in probability theory.
In this modern-day labyrinth tale, two groups of researchers played the role of Ariadne to my wandering Theseus: Yiming Huang and Marco Valtorta at the University of South Carolina and my own student, Ilya Shpitser, at the University of California, Los Angeles (UCLA). Both groups independently and simultaneously proved that Rules 1 to 3 suffice to get out of any do -labyrinth that has an exit. I am not sure whether the world was waiting breathlessly for their completeness result, because by then most researchers had become content with just using the front- and back-door criteria. Both teams were, however, recognized with best student paper awards at the Uncertainty in Artificial Intelligence conference in 2006.
I confess that I was the one waiting breathlessly for this result. It tells us that if we cannot find a way to estimate P Y ( | do X ( )) from Rules 1 to 3, then a solution does not exist. In that case, we know that there is no alternative to conducting a randomized controlled trial. It further tells us what additional assumptions or experiments might make the causal effect estimable.
Before declaring total victory, we should discuss one issue with the do -calculus. Like any other calculus, it enables the construction of a proof, but it does not help us find one. It is an excellent verifier of a solution but not such a good searcher for one. If you know the correct sequence of transformations, it is easy to demonstrate to others (who are familiar with Rules 1 to 3) that the do -operator can be eliminated. However, if you do not know the correct sequence, it is not easy to discover it, or even to determine whether one exists. Using the analogy with geometrical proofs, we need to decide which auxiliary construction to try next. A circle around point A ? A line parallel to AB ? The number of possibilities is limitless, and the axioms themselves provide no guidance about what to try next. My high school geometry teacher used to say
that you need 'mathematical eyeglasses.'
In mathematical logic, this is known as the 'decision problem.' Many logical systems are plagued with intractable decision problems. For instance, given a pile of dominos of various sizes, we have no tractable way to decide if we can arrange them to fill a square of a given size. But once an arrangement is proposed, it takes no time at all to verify whether it constitutes a solution.
Luckily (again) for do -calculus, the decision problem turns out to be manageable. Ilya Shpitser, building on earlier work by one of my other students, Jin Tian, found an algorithm that decides if a solution exists in 'polynomial time.' This is a somewhat technical term, but continuing our analogy with solving a maze, it means that we have a much more efficient way out of the labyrinth than hunting at random through all possible paths.
Shpitser's algorithm for finding each and every causal effect does not eliminate the need for the do -calculus. In fact, we need it even more, and for several independent reasons. First, we need it in order to go beyond observational studies. Suppose that worst comes to worst, and our causal model does not permit estimation of the causal effect P Y ( | do X ( )) from observations alone. Perhaps we also cannot conduct a randomized experiment with random assignment of X . A clever researcher might ask whether we might estimate P Y ( | do X ( )) by randomizing some other variable, say Z , that is more accessible to control than X . For instance, if we want to assess the effect of cholesterol levels ( X ) on heart disease ( Y ), we might be able to manipulate the subjects' diet ( Z ) instead of exercising direct control over the cholesterol levels in their blood.
We then ask if we can find such a surrogate Z that will enable us to answer the causal question. In the world of do -calculus, the question is whether we can find a Z such that we can transform P Y ( | do X ( )) into an expression in which the variable Z , but not X , is subjected to a do -operator. This is a completely different problem not covered by Shpitser's algorithm. Luckily, it has a complete answer too, with a new algorithm discovered by Elias Bareinboim at my lab in 2012. Even more problems of this sort arise when we consider problems of transportability or external validity-assessing whether an experimental result will still be valid when transported to a different environment that may differ in several key ways from the one studied. This more ambitious set of questions touches on the heart of scientific methodology, for there is no science without generalization. Yet the question of generalization has been lingering for at least two centuries, without an iota of progress. The tools for producing a solution were simply not available. In
2015, Bareinboim and I presented a paper at the National Academy of Sciences that solves the problem, provided that you can express your assumptions about both environments with a causal diagram. In this case the rules of do -calculus provide a systematic method to determine whether causal effects found in the study environment can help us estimate effects in the intended target environment.
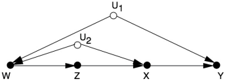
Yet another reason that the do -calculus remains important is transparency. As I wrote this chapter, Bareinboim (now a professor at Purdue) sent me a new puzzle: a diagram with just four observed variables, X Y Z , , , and W , and two unobservable variables, U 1 , U 2 (see Figure 7.5). He challenged me to figure out if the effect of X on Y was estimable. There was no way to block the back-door paths and no front-door condition. I tried all my favorite shortcuts and my otherwise trustworthy intuitive arguments, both pro and con, and I couldn't see how to do it. I could not find a way out of the maze. But as soon as Bareinboim whispered to me, 'Try the do -calculus,' the answer came shining through like a baby's smile. Every step was clear and meaningful. This is now the simplest model known to us in which the causal effect needs to be estimated by a method that goes beyond the front- and back-door adjustments.
FIGURE 7.5. A new napkin problem?
In order not to leave the reader with the impression that the do -calculus is good only for theory and to serve as a recreational brainteaser, I will end this section with a practical problem recently brought up by two leading statisticians, Nanny Wermuth and David Cox. It demonstrates how a friendly whisper, 'Try the do -calculus,' can help expert statisticians solve difficult practical problems.
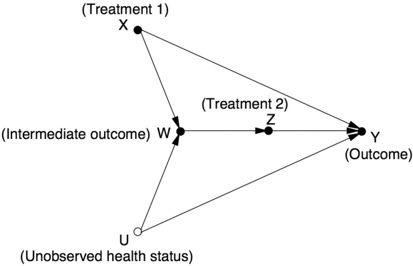
Around 2005, Wermuth and Cox became interested in a problem called 'sequential decisions' or 'time-varying treatments,' which are common, for example, in the treatment of AIDS. Typically treatments are administered over a length of time, and in each time period physicians vary the strength and dosage of a follow-up treatment according to the patient's condition. The patient's condition, on the other hand, is influenced by the treatments taken in the past. We thus end up with a scenario like the one depicted in Figure 7.6, showing two time periods and two treatments. The first treatment is randomized ( X ), and the second ( Z ) is given in response to an observation ( W )
that depends on X . Given data collected under such a treatment regime, Cox and Wermuth's task was to predict the effect of X on the outcome Y , assuming that they were to keep Z constant through time, independent of the observation W .
FIGURE 7.6. Wermuth and Cox's example of a sequential treatment.
Jamie Robins first brought the problem of time-varying treatments to my attention in 1994, and with the help of do -calculus, we were able to derive a general solution invoking a sequential version of the back-door adjustment formula. Wermuth and Cox, unaware of this method, called their problem 'indirect confounding' and published three papers on its analysis (2008, 2014, and 2015). Unable to solve it in general, they resorted to a linear approximation, and even in the linear case they found it difficult to handle, because it is not solvable by standard regression methods.
Fortunately, when a muse whispered in my ear, 'Try the do -calculus,' I noticed that their problem can be solved in three lines of calculation. The logic goes as follows. Our target quantity is P Y ( | do X ( ), do Z ( )), while the data we have available to us are of the form P Y ( | do X ( ), Z W , ) and P W ( | do X ( )). These reflect the fact that, in the study from which we have data, Z is not controlled externally but follows W through some (unknown) protocol. Thus, our task is to transform the target expression to another expression, reflecting the study conditions in which the do -operator applies only to X and not to Z . It so happens that a single application of the three rules of do -calculus can accomplish this. The moral of the story is nothing but a deep appreciation of the power of mathematics to solve difficult problems, which occasionally entail practical consequences.
THE TAPESTRY OF SCIENCE, OR THE HIDDEN PLAYERS IN THE DO -ORCHESTRA
I've already mentioned the role of some of my students in weaving this beautiful do -calculus tapestry. Like any tapestry, it gives a sense of completeness that may conceal how painstaking making it was and how many hands contributed to the process. In this case, it took more than twenty years and contributions from several students and colleagues.
The first was Thomas Verma, whom I met when he was a sixteen-year-old boy. His father brought him to my office one day and said, essentially, 'Give him something to do.' He was too talented for any of his high school math teachers to keep him interested. What he eventually accomplished was truly amazing. Verma finally proved what became known as the d -separation property (i.e., the fact that you can use the rules of path blocking to determine which independencies should hold in the data). Astonishingly, he told me that he proved the d -separation property thinking it was a homework problem, not an unsolved conjecture! Sometimes it pays to be young and naive. You can still see his legacy in Rule 1 of the do -calculus and in any imprint that path blocking leaves on rung one of the Ladder of Causation.
The power of Verma's proof would have remained only partially appreciated without a complementary result to show that it cannot be improved. That is, no other independencies are implied by a causal diagram except those revealed through path blocking. This step was completed by another student, Dan Geiger. He had switched to my research lab from another group at UCLA, after I promised to give him an 'instant PhD' if he could prove two theorems. He did, and I did! He is now Dean of computer science at the Technion in Israel, my alma mater.
But Dan was not the only student I raided from another department. One day in 1997, as I was getting dressed in the locker room of the UCLA pool, I struck up a conversation with a Chinese fellow next to me. He was a PhD student in physics, and, as was my usual habit at the time, I tried to convince him to switch over to artificial intelligence, where the action was. He was not completely convinced, but the very next day I received an email from a friend of his, Jin Tian, saying that he would like to switch from physics to computer science and did I have a challenging summer project for him? Two days later, he was working in my lab.
Four years later, in April 2001, he stunned the world with a simple graphical criterion that generalizes the front door, the back door, and all doors we could think of at the time. I recall presenting Tian's criterion at a Santa Fe conference. One by one, leaders in the research community stared at my poster and shook their heads in disbelief. How could such a simple criterion
work for all diagrams?
Tian (now a professor at Iowa State University) came to our lab with a style of thinking that was foreign to us then, in the 1990s. Our conversations were always loaded with wild metaphors and half-baked conjectures. But Tian would never utter a word unless it was rigorous, proven, and baked five times over. The mixture of the two styles proved its merit. Tian's method, called c -decomposition, enabled Ilya Shpitser to develop his complete algorithm for the do -calculus. The moral: never underestimate the power of a locker-room conversation!
Ilya Shpitser came in at the end of the ten-year battle to understand interventions. He arrived during a very difficult period, when I had to take time off to set up a foundation in honor of my son, Daniel, a victim of antiWestern terrorism. I have always expected my students to be self-reliant, but for my students at that time, this expectation was pushed to the extreme. They gave me the best of all possible gifts by putting the final but crucial touches on the tapestry of do -calculus, which I could not have done myself. In fact, I tried to discourage Ilya from trying to prove the completeness of do -calculus. Completeness proofs are notoriously difficult and are best avoided by any student who aims to finish his PhD on time. Luckily, Ilya did it behind my back.
Colleagues, too, exert a profound effect on your thinking at crucial moments. Peter Spirtes, a professor of philosophy at Carnegie-Mellon, preceded me in the network approach to causality, and his influence was pivotal. At a lecture of his in Uppsala, Sweden, I first learned that performing interventions could be thought of as deleting arrows from a causal diagram. Until then I had been laboring under the same burden as generations of statisticians, trying to think of causality in terms of only one diagram representing one static probability distribution.
The idea of arrow deletion was not entirely Spirtes's, either. In 1960, two Swedish economists, Robert Strotz and Herman Wold, proposed essentially the same idea. In the world of economics at the time, diagrams were never used; instead, economists relied on structural equation models, which are Sewall Wright's equations without the diagrams. Arrow deletion in a path diagram corresponds to deleting an equation from a structural equation model. So, in a rough sense, Strotz and Wold had the idea first, unless we want to go even further back in history: they were preceded by Trygve Haavelmo (a Norwegian economist and Nobel laureate), who in 1943 advocated equation modification to represent interventions.
Nevertheless, Spirtes's translation of equation deletion into the world of causal diagrams unleashed an avalanche of new insights and new results. The back-door criterion was one of the first beneficiaries of the translation, while the do -calculus came second. The avalanche, however, is not yet over. Advances in such areas as counterfactuals, generalizability, missing data, and machine learning are still coming up.
If I were less modest, I would close here with Isaac Newton's famous saying about 'standing on the shoulders of giants.' But given who I am, I am tempted to quote from the Mishnah instead: 'Harbe lamadeti mirabotai um'haverai yoter mehem, umitalmidai yoter mikulam'-that is, 'I have learned much from my teachers, and more so from my colleagues, and most of all from my students' (Taanit 7a). The do -operator and do -calculus would not exist as they do today without the contributions of Verma, Geiger, Tian, and Shpitser, among others.
THE CURIOUS CASE(S) OF DR. SNOW
In 1853 and 1854, England was in the grips of a cholera epidemic. In that era, cholera was as terrifying as Ebola is today; a healthy person who drinks cholera-tainted water can die within twenty-four hours. We know today that cholera is caused by a bacterium that attacks the intestines. It spreads through the 'rice water' diarrhea of its victims, who excrete this diarrhea in copious amounts before dying.
But in 1853, disease-causing germs had never yet been seen under a microscope for any illness, let alone cholera. The prevailing wisdom held that a 'miasma' of unhealthy air caused cholera, a theory seemingly supported by the fact that the epidemic hit harder in the poorer sections of London, where sanitation was worse.
Dr. John Snow, a physician who had taken care of cholera victims for more than twenty years, was always skeptical of the miasma theory. He argued, sensibly, that since the symptoms manifested themselves in the intestinal tract, the body must first come into contact with the pathogen there. But because he couldn't see the culprit, he had no way to prove this-until the epidemic of 1854.
The John Snow story has two chapters, one much more famous than the other. In what we could call the 'Hollywood' version, he painstakingly goes from house to house, recording where victims of cholera died, and notices a
cluster of dozens of victims near a pump in Broad Street. Talking with people who live in the area, he discovers that almost all the victims had drawn their water from that particular pump. He even learns of a fatal case that occurred far away, in Hampstead, to a woman who liked the taste of the water from the Broad Street pump. She and her niece drank the water from Broad Street and died, while no one else in her area even got sick. Putting all this evidence together, Snow asks the local authorities to remove the pump handle, and on September 8 they agree. As Snow's biographer wrote, 'The pump-handle was removed, and the plague was stayed.'
All of this makes a wonderful story. Nowadays a John Snow Society even reenacts the removal of the famous pump handle every year. Yet, in truth, the removal of the pump handle hardly made a dent in the citywide cholera epidemic, which went on to claim nearly 3,000 lives.
In the non-Hollywood chapter of the story, we again see Dr. Snow walking the streets of London, but this time his real object is to find out where Londoners get their water. There were two main water companies at the time: the Southwark and Vauxhall Company and the Lambeth Company. The key difference between the two, as Snow knew, was that the former drew its water from the area of the London Bridge, which was downstream from London's sewers. The latter had moved its water intake several years earlier so that it would be upstream of the sewers. Thus, Southwark customers were getting water tainted by the excrement of cholera victims. Lambeth customers, on the other hand, were getting uncontaminated water. (None of this has anything to do with the contaminated Broad Street water, which came from a well.)
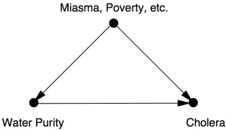
The death statistics bore out Snow's grim hypothesis. Districts supplied by the Southwark and Vauxhall Company were especially hard-hit by cholera and had a death rate eight times higher. Even so, the evidence was merely circumstantial. A proponent of the miasma theory could argue that the miasma was strongest in those districts, and there would be no way to disprove it. In terms of a causal diagram, we have the situation diagrammed in Figure 7.7. We have no way to observe the confounder Miasma (or other confounders like Poverty), so we can't control for it using back-door adjustment.
Here Snow had his most brilliant idea. He noticed that in those districts served by both companies, the death rate was still much higher in the households that received Southwark water. Yet these households did not differ in terms of miasma or poverty. 'The mixing of the supply is of the most intimate kind,' Snow wrote. 'The pipes of each Company go down all the streets, and into nearly all the courts and alleys.… Each company supplies
both rich and poor, both large houses and small; there is no difference either in the condition or occupation of the persons receiving the water of the different Companies.' Even though the notion of an RCT was still in the future, it was very much as if the water companies had conducted a randomized experiment on Londoners. In fact, Snow even notes this: 'No experiment could have been devised which would more thoroughly test the effect of water supply on the progress of cholera than this, which circumstances placed ready made before the observer. The experiment, too, was on the grandest scale. No fewer than three hundred thousand people of both sexes, of every age and occupation, and of every rank and station, from gentlefolks down to the very poor, were divided into two groups without their choice, and in most cases, without their knowledge.' One group had received pure water; the other had received water tainted with sewage.
FIGURE 7.7. Causal diagram for cholera (before discovery of the cholera bacillus).
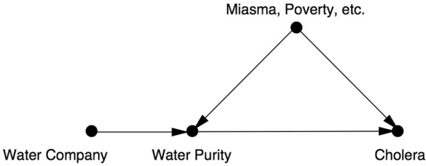
Snow's observations introduced a new variable into the causal diagram, which now looks like Figure 7.8. Snow's painstaking detective work had showed two important things: (1) there is no arrow between Miasma and Water Company (the two are independent), and (2) there is an arrow between Water Company and Water Purity. Left unstated by Snow, but equally important, is a third assumption: (3) the absence of a direct arrow from Water Company to Cholera, which is fairly obvious to us today because we know the water companies were not delivering cholera to their customers by some alternate route.
FIGURE 7.8. Diagram for cholera after introduction of an instrumental variable.
A variable that satisfies these three properties is today called an instrumental variable. Clearly Snow thought of this variable as similar to a coin flip, which simulates a variable with no incoming arrows. Because there are no confounders of the relation between Water Company and Cholera, any
observed association must be causal. Likewise, since the effect of Water Company on Cholera must go through Water Purity, we conclude (as did Snow) that the observed association between Water Purity and Cholera must also be causal. Snow stated his conclusion in no uncertain terms: if the Southwark and Vauxhall Company had moved its intake point upstream, more than 1,000 lives would have been saved.
Few people took note of Snow's conclusion at the time. He printed a pamphlet of the results at his own expense, and it sold a grand total of fiftysix copies. Nowadays, epidemiologists view his pamphlet as the seminal document of their discipline. It showed that through 'shoe-leather research' (a phrase I have borrowed from David Freedman) and causal reasoning, you can track down a killer.
Although the miasma theory has by now been discredited, poverty was undoubtedly a confounder, as was location. But even without measuring these (because Snow's door-to-door detective work only went so far), we can still use instrumental variables to determine how many lives would have been saved by purifying the water supply.
Here's how the trick works. For simplicity we'll go back to the names Z , X Y , , and U for our variables and redraw Figure 7.8 as seen in Figure 7.9. I have included path coefficients ( a , b , c , d ) to represent the strength of the causal effects. This means we are assuming that the variables are numerical and the functions relating them are linear. Remember that the path coefficient a means that an intervention to increase Z by one standard unit will cause X to increase by a standard units. (I will omit the technical details of what the 'standard units' are.)
FIGURE 7.9. General setup for instrumental variables.
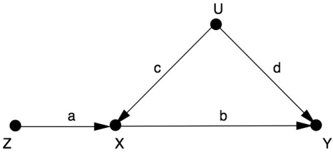
Because Z and X are unconfounded, the causal effect of Z on X (that is, a ) can be estimated from the slope r XZ of the regression line of X on Z . Likewise, the variables Z and Y are unconfounded, because the path Z X U Y is blocked by the collider at X . So the slope of the regression line of Z on Y ( r ZY ) will equal the causal effect on the direct path Z X Y , which is the product of the path coefficients: ab . Thus we have two equations: ab = r ZY
and a = r ZX . If we divide the first equation by the second, we get the causal effect of X on Y b : = r ZY / r ZX .
In this way, instrumental variables allow us to perform the same kind of magic trick that we did with front-door adjustment: we have found the effect of X on Y even without being able to control for, or collect data on, the confounder, U . We can therefore provide decision makers with a conclusive argument that they should move their water supply-even if those decision makers still believe in the miasma theory. Also notice that we have gotten information on the second rung of the Ladder of Causation ( b ) from information about the first rung (the correlations, r ZY and r ZX ). We were able to do this because the assumptions embodied in the path diagram are causal in nature, especially the crucial assumption that there is no arrow between U and Z . If the causal diagram were different-for example, if Z were a confounder of X and Y -the formula b = r ZY / r ZX would not correctly estimate the causal effect of X on Y . In fact, these two models cannot be told apart by any statistical method, regardless of how big the data.
Instrumental variables were known before the Causal Revolution, but causal diagrams have brought new clarity to how they work. Indeed, Snow was using an instrumental variable implicitly, although he did not have a quantitative formula. Sewall Wright certainly understood this use of path diagrams; the formula b = r ZY / r ZX can be derived directly from his method of path coefficients. And it seems that the first person other than Sewall Wright to use instrumental variables in a deliberate way was… Sewall Wright's father, Philip!
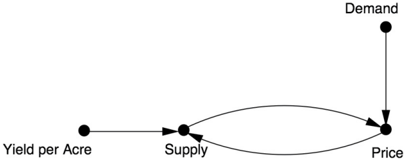
Recall that Philip Wright was an economist who worked at what later became the Brookings Institution. He was interested in predicting how the output of a commodity would change if a tariff were imposed, which would raise the price and therefore, in theory, encourage production. In economic terms, he wanted to know the elasticity of supply.
In 1928 Wright wrote a long monograph dedicated to computing the elasticity of supply for flaxseed oil. In a remarkable appendix, he analyzed the problem using a path diagram. This was a brave thing to do: remember that no economist had ever seen or heard of such a thing before. (In fact, he hedged his bets and verified his calculations using more traditional methods.)
Figure 7.10 shows a somewhat simplified version of Wright's diagram. Unlike most diagrams in this book, this one has 'two-way' arrows, but I would ask the reader not to lose too much sleep over it. With some
mathematical trickery we could equally well replace the Demand Price Supply chain with a single arrow Demand Supply, and the figure would then look like Figure 7.9 (though it would be less acceptable to economists). The important point to note is that Philip Wright deliberately introduced the variable Yield per Acre (of flaxseed) as an instrument that directly affects supply but has no correlation to demand. He then used an analysis like the one I just gave to deduce both the effect of supply on price and the effect of price on supply.
FIGURE 7.10. Simplified version of Wright's supply-price causal diagram.
Historians quarrel about who invented instrumental variables, a method that became extremely popular in modern econometrics. There is no question in my mind that Philip Wright borrowed the idea of path coefficients from his son. No economist had ever before insisted on the distinction between causal coefficients and regression coefficients; they were all in the Karl PearsonHenry Niles camp that causation is nothing more than a limiting case of correlation. Also, no one before Sewall Wright had ever given a recipe for computing regression coefficients in terms of path coefficients, then reversing the process to get the causal coefficients from the regression. This was Sewall's exclusive invention.
Naturally, some economic historians have suggested that Sewall wrote the whole mathematical appendix himself. However, stylometric analysis has shown that Philip was indeed the author. To me, this historical detective work makes the story more beautiful. It shows that Philip took the trouble to understand his son's theory and articulate it in his own language.
Now let's move forward from the 1850s and 1920s to look at a present-day example of instrumental variables in action, one of literally dozens I could have chosen.
GOOD AND BAD CHOLESTEROL
Do you remember when your family doctor first started talking to you about 'good' and 'bad' cholesterol? It may have happened in the 1990s, when
drugs that lowered blood levels of 'bad' cholesterol, low-density lipoprotein (LDL), first came on the market. These drugs, called statins, have turned into multibillion-dollar revenue generators for pharmaceutical companies.
The first cholesterol-modifying drug subjected to a randomized controlled trial was cholestyramine. The Coronary Primary Prevention Trial, begun in 1973 and concluded in 1984, showed a 12.6 percent reduction in cholesterol among men given the drug cholestyramine and a 19 percent reduction in the risk of heart attack.
Because this was a randomized controlled trial, you might think we wouldn't need any of the methods in this chapter, because they are specifically designed to replace RCTs in situations where you only have observational data. But that is not true. This trial, like many RCTs, faced the problem of noncompliance, when subjects randomized to receive a drug don't actually take it. This will reduce the apparent effectiveness of the drug, so we may want to adjust the results to account for the noncompliers. But as always, confounding rears its ugly head. If the noncompliers are different from the compliers in some relevant way (maybe they are sicker to start with?), we cannot predict how they would have responded had they adhered to instructions.
In this situation, we have a causal diagram that looks like Figure 7.11. The variable Assigned ( Z ) will take the value 1 if the patient is randomly assigned to receive the drug and 0 if he is randomly assigned a placebo. The variable Received will be 1 if the patient actually took the drug and 0 otherwise. For convenience, we'll also use a binary definition for Cholesterol, recording an outcome of 1 if the cholesterol levels were reduced by a certain fixed amount.
FIGURE 7.11. Causal diagram for an RCT with noncompliance.
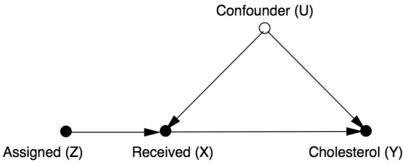
Notice that in this case our variables are binary, not numerical. This means right away that we cannot use a linear model, and therefore we cannot apply the instrumental variables formula that we derived earlier. However, in such cases we can often replace the linearity assumption with a weaker condition called monotonicity, which I'll explain below.
But before we do that, let's make sure our other necessary assumptions for
instrumental variables are valid. First, is the instrumental variable Z independent of the confounder? The randomization of Z ensures that the answer is yes. (As we saw in Chapter 4, randomization is a great way to make sure that a variable isn't affected by any confounders.) Is there any direct path from Z to Y ? Common sense says that there is no way that receiving a particular random number ( Z ) would affect cholesterol ( Y ), so the answer is no. Finally, is there a strong association between Z and X ? This time the data themselves should be consulted, and the answer again is yes. We must always ask the above three questions before we apply instrumental variables. Here the answers are obvious, but we should not be blind to the fact that we are using causal intuition to answer them, intuition that is captured, preserved, and elucidated in the diagram.
Table 7.1 shows the observed frequencies of outcomes X and Y . For example, 91.9 percent of the people who were not assigned the drug had the outcome X = 0 (didn't take drug) and Y = 0 (no reduction in cholesterol). This makes sense. The other 8.1 percent had the outcome X = 0 (didn't take drug) and Y = 1 (did have a reduction in cholesterol). Evidently they improved for other reasons than taking the drug. Notice also that there are two zeros in the table: there was nobody who was not assigned the drug ( Z = 0) but nevertheless procured some ( X = 1). In a well-run randomized study, especially in the medical field where the physicians have exclusive access to the experimental drug, this will typically be true. The assumption that there are no individuals with Z = 0 and X = 1 is called monotonicity.
TABLE 7.1. Data from cholestyramine trial.
Now let's see how we can estimate the effect of the treatment. First let's take the worst-case scenario: none of the noncompliers would have improved if they had complied with treatment. In that case, the only people who would have taken the drug and improved would be the 47.3 percent who actually did comply and improve. But we need to correct this estimate for the placebo effect, which is in the third row of the table. Out of the people who were assigned the placebo and took the placebo, 8.1 percent improved. So the net improvement above and beyond the placebo effect is 47.3 percent minus 8.1
percent, or 39.2 percent.
What about the best-case scenario, in which all the noncompliers would have improved if they had complied? In this case we add the noncompliers' 31.5 percent plus 7.3 percent to the 39.2 percent baseline we just computed, for a total of 78.0 percent.
Thus, even in the worst-case scenario, where the confounding goes completely against the drug, we can still say that the drug improves cholesterol for 39 percent of the population. In the best-case scenario, where the confounding works completely in favor of the drug, 78 percent of the population would see an improvement. Even though the bounds are quite far apart, due to the large number of noncompliers, the researcher can categorically state that the drug is effective for its intended purpose.
This strategy of taking the worst case and then the best case will usually give us a range of estimates. Obviously it would be nice to have a point estimate, as we did in the linear case. There are ways to narrow the range if necessary, and in some cases it is even possible to get point estimates. For example, if you are interested only in the complying subpopulation (those people who will take X if and only if assigned), you can derive a point estimate known as the Local Average Treatment Effect (LATE). In any event, I hope this example shows that our hands are not tied when we leave the world of linear models.
Instrumental variable methods have continued to develop since 1984, and one particular version has become extremely popular: Mendelian randomization. Here's an example. Although the effect of LDL, or 'bad,' cholesterol is now settled, there is still considerable uncertainty about highdensity lipoprotein (HDL), or 'good,' cholesterol. Early observational studies, such as the Framingham Heart Study in the late 1970s, suggested that HDL had a protective effect against heart attacks. But high HDL often goes hand in hand with low LDL, so how can we tell which lipid is the true causal factor?
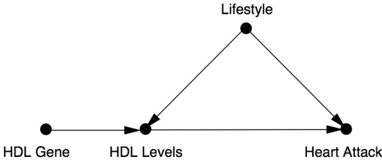
To answer this question, suppose we knew of a gene that caused people to have higher HDL levels, with no effect on LDL. Then we could set up the causal diagram in Figure 7.12, where I have used Lifestyle as a possible confounder. Remember that it is always advantageous, as in Snow's example, to use an instrumental variable that is randomized. If it's randomized, no causal arrows point toward it. For this reason, a gene is a perfect instrumental variable. Our genes are randomized at the time of conception, so it's just as if Gregor Mendel himself had reached down from heaven and assigned some
people a high-risk gene and others a low-risk gene. That's the reason for the term 'Mendelian randomization.'
Could there be an arrow going the other way, from HDL Gene to Lifestyle? Here we again need to do 'shoe-leather work' and think causally. The HDL gene could only affect people's lifestyle if they knew which version they had, the high-HDL version or the low-HDL one. But until 2008 no such genes were known, and even today, people do not routinely have access to this information. So it's highly likely that no such arrow exists.
Figure 7.12. Causal diagram for Mendelian randomization example.
At least two studies have taken this Mendelian randomization approach to the cholesterol question. In 2012, a giant collaborative study led by Sekar Kathiresan of Massachusetts General Hospital showed that there was no observable benefit from higher HDL levels. On the other hand, the researchers found that LDL has a very large effect on heart attack risk. According to their figures, decreasing your LDL count by 34 mg/dl would reduce your chances of a heart attack by about 50 percent. So lowering your 'bad' cholesterol levels, whether by diet or exercise or statins, seems to be a smart idea. On the other hand, increasing your 'good' cholesterol levels, despite what some fish-oil salesmen might tell you, does not seem likely to change your heart attack risk at all.
As always, there is a caveat. The second study, published in the same year, pointed out that people with the lower-risk variant of the LDL gene have had lower cholesterol levels for their entire lives. Mendelian randomization tells us that decreasing your LDL by thirty-four units over your entire lifetime will decrease your heart attack risk by 50 percent. But statins can't lower your LDL cholesterol over your entire lifetime-only from the day you start taking the drug. If you're sixty years old, your arteries have already sustained sixty years of damage. For that reason it's very likely that Mendelian randomization overestimates the true benefits of statins. On the other hand, starting to reduce your cholesterol when you're young-whether through diet or exercise or even statins-will have big effects later.
From the point of view of causal analysis, this teaches us a good lesson: in any study of interventions, we need to ask whether the variable we're actually
manipulating (lifetime LDL levels) is the same as the variable we think we are manipulating (current LDL levels). This is part of the 'skillful interrogation of nature.'
To sum up, instrumental variables are an important tool in that they help us uncover causal information that goes beyond the do -calculus. The latter insists on point estimates rather than inequalities and would give up on cases like Figure 7.12, in which all we can get are inequalities. On the other hand, it's also important to realize that the do -calculus is vastly more flexible than instrumental variables. In do -calculus we make no assumptions whatsoever regarding the nature of the functions in the causal model. But if we can justify an assumption like monotonicity or linearity on scientific grounds, then a more special-purpose tool like instrumental variables is worth considering.
Instrumental variable methods can be extended beyond simple fourvariable models like Figure 7.9 (or 7.11 or 7.12), but it is not possible to go very far without guidance from causal diagrams. For example, in some cases an imperfect instrument (e.g., one that is not independent of the confounder) can be used after conditioning on a cleverly chosen set of auxiliary variables, which block the paths between the instrument and the confounder. My former student Carlos Brito, now a professor at the Federal University of Ceara, Brazil, fully developed this idea of turning noninstrumental variables into instrumental variables.
In addition, Brito studied many cases where a set of variables can be used successfully as an instrument. Although the identification of instrumental sets goes beyond do -calculus, it still uses the tools of causal diagrams. For researchers who understand this language, the possible research designs are rich and varied; they need not feel constrained to use only the four-variable model shown in Figures 7.9, 7.11, and 7.12. The possibilities are limited only by our imaginations.

Robert Frost's famous lines show a poet's acute insight into counterfactuals. We cannot travel both roads, and yet our brains are equipped to judge what would have happened if we had taken the other path. Armed with this judgment, Frost ends the poem pleased with his choice, realizing that it 'made all the difference.' ( Source: Drawing by Maayan Harel.)