Time Series
Reasoning about causal relations among variables that refer to different time instances is easier than causal reasoning without time structure. Causal structures have to be consistent with the time order. We have seen in Section 7.2.4 that, after knowing a causal ordering of nodes and assuming that there are no hidden variables, finding the causal DAG does not require assumptions other than the Markov condition and minimality (more debatable conditions such as faithfulness or restricted function classes, for instance, are not necessary). Given the time order, three main issues remain. First, the set of variables under consideration may not be causally sufficient; second, there may be variables that refer to the same time instant (within the given measurement accuracy) that cannot be causally ordered a priori; third, in practice, we are often given only one repetition of the time series—this differs from the usual i.i.d. setting, in which we observe every variable several times. Accordingly, all these issues play a crucial role for causal reasoning in time series.
Preliminaries and Terminology
So far, we have considered a setting where samples are i.i.d. drawn from the joint distribution P*{X₁,...,X_d}. Here, we discuss causal inference in time series, that is, we have a d-variate time series (X_t)*{t∈ℤ}, where each X_t for fixed t is the vector (X^1_t, ..., X^d_t). We assume that it describes a strictly stationary stochastic process [e.g., Brockwell and Davis, 1991]. Each variable X^j_t represents a measurement of the jth observable of some system at time t. Since causal influence can never go from the future to the past, we distinguish between two types of causal relations in multivariate time series.
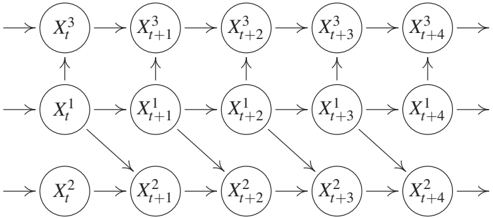
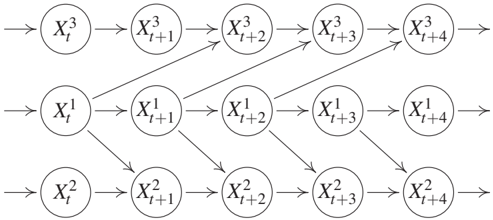
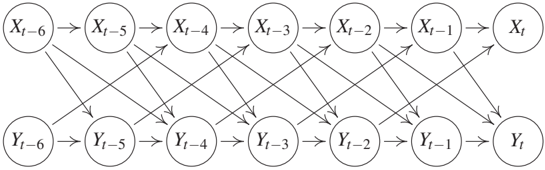
First, the causal graph with nodes X^jt for (j,t) ∈ {1,...,d} × ℤ contains only arrows from X^j_t to X^k_s for t < s but not for t = s; see Figure 10.1. Then we say there are no instantaneous effects. Second, the causal graph contains instantaneous effects, that is, arrows from X^j_t to X^k_t for some j and k in addition to arrows going from X^m_t to X^ℓ_s for t < s and some m and ℓ, as shown in Figure 10.2. We call the causal structure purely instantaneous if for any j ≠ k and h > 0 the variable X^j_t may influence X^k_t and X^j{t+h} but not X^k_{t+h}; see Figures 10.5(a) and 10.5(b). The case where each X^j_t is not influenced by any previous variable (including its own past), can be ignored because it need not be described as time series. Instead, the index t may then be considered as labeling indices of independent instances of a statistical sample in the i.i.d. setting of previous chapters.
We define the full time graph as the DAG having X^i_t as nodes, as visualized in Figures 10.1 and 10.2. In contrast to previous chapters, the full time graph is a DAG with infinitely many nodes. The summary graph is the directed graph with nodes X₁, ..., X_d containing an arrow from X_j to X_k for j ≠ k whenever there is an arrow from X^j_t to X^k_s for some t ≤ s ∈ ℤ. Note that the summary graph is a directed graph that may contain cycles, although we will assume that the full time graph is acyclic. Figure 10.3 shows the summary graph corresponding to the full time graphs depicted in Figures 10.1 and 10.2.

For any t ∈ ℤ, we denote by X*{past}(t) the set of all X_s with s < t and use X^j*{past}(t) for the past of a specific component X^j. We also write X^j*{past} if t is some fixed time instant of reference. Moreover, (X^{-j}_t){t∈ℤ} denotes the collection of time series (X^kt)*{t∈ℤ} for all k ≠ j.
Structural Causal Models and Interventions
We assume that the stochastic process (Xt){t∈ℤ} admits a description by an SCM in which at most the past q values (for some q) of all variables occur:
$$X^j_t := f_j((PA^j_q){t-q}, ..., (PA^j_1){t-1}, (PA^j_0)_t, N^j_t),$$ (10.1)
where
$$..., N^1_{t-1}, ..., N^d_{t-1}, N^1_t, ..., N^d_t, N^1_{t+1}, ..., N^d_{t+1}, ...$$
are jointly independent noise terms. Here, for each s ∈ ℤ, the symbol (PA^js){t-s} denotes the set of variables X^k*{t-s}, k = 1, ..., d, that influence X^j_t. Note that PA^j*{t-s} may contain X^j_{t-s} for all s > 0, but not for s = 0. We assume the corresponding full time graph to be acyclic.
A popular special case of (10.1) is the class of vector autoregressive models (VAR) [Lütkepohl, 2007]:
$$X^j_t := \sum_{i=1}^q A_{ji} X_{t-i} + N^j_t,$$ (10.2)
where each A_{ji} is a 1 × d-matrix; see also Remark 6.5 on linear cyclic models, especially Equation (6.4).
As in the i.i.d. setting, SCMs formalize the effect of interventions; more precisely, an intervention corresponds to replacing some of the structural assignments. Interventions may, for instance, consist in setting all values {X^jt}{t∈ℤ} for some j to certain values. Alternatively, one could also intervene on X^j_t only at one specific time instant t.
Subsampling
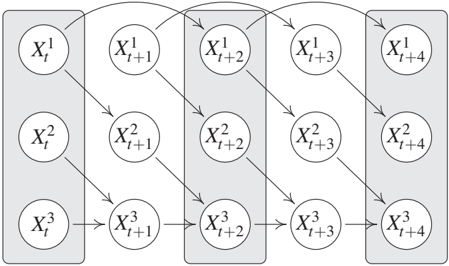
In many applications, the sampling process may be slower than the time scale of the causal processes. Figure 10.4 shows an example, in which only every second time instance is observed. The summary graph of the original full system contains the edges X₁ → X₂ → X₃. We may now want to construct a causal model for the observed, subsampled processes. It is therefore important to define which interventions we want to allow for. First, if we constrain ourselves to interventions on observed time points, there should be no causal influence from X₁ to X₂. Intervening on an observed instance of X₁ does not have any effect on the observable part of X₂ (note that the time series X₁ has only lag two effects X^1t → X^1{t+2}). Furthermore, in this setting, subsampling cannot create spurious instantaneous effects if these have not been there before. For the case of an SCM, Bongers et al. [2016, Chapter 3] describe a formal process of how to marginalize the model by substituting the causal mechanisms of the hidden time steps into the other mechanisms. The resulting model describes the effect of interventions correctly if these are restricted to the observed time points. Second, if we do consider interventions on hidden variables, however, we may be interested in recovering the original summary graph, a problem that is addressed by Danks and Plis [2013] and Hyttinen et al. [2016], for example.
There are situations in which subsampling is not a good model for the data-generating process. For many physical measurements, for example, one may want to model the observations as averages of consecutive time points rather than as a sparse subset of those. The former is a useful but also complicated model assumption: the averaging process might change the model class, and one furthermore needs to be careful about modeling interventions.
Learning Causal Time Series Models
Currently, Granger causality and its variations is among the most popular approaches to causal time series analysis. To provide a better link among the chapters, we nevertheless first explain the conclusions that can be drawn using a conditional independence-based approach. The order should by no means be mistaken as a judgment about the approaches.
Sections 10.3.1 and 10.3.2 contain mostly identifiability results. The remaining three Sections, 10.3.3, 10.3.4, and 10.3.5, contain more concrete causal learning methods for time series. They can be applied if the multivariate time series has been sampled once, at finitely many time points. Most of the ideas, however, transfer to situations, where we receive several i.i.d. repetitions of the same time series.
Markov Condition and Faithfulness
Lemma 6.25 states that two DAGs are Markov equivalent if and only if their skeleton and their set of v-structures coincide. If there are no instantaneous effects, the full time graph is therefore already determined by knowing its skeleton. The arrow can only be directed forward in time. We thus conclude [Peters et al., 2013, Proof of Theorem 1]:
Theorem 10.1 (Identifiability in absence of instantaneous effects) Assume that two full time graphs are induced by SCMs without instantaneous effects. If the full time graphs are Markov equivalent, then they are equal.
Hence, we can uniquely identify the full time graph from conditional independences provided that Markov condition and faithfulness holds (to deal with infinitely large DAGs, one sometimes assumes that the time series start at t = 0).
In the presence of instantaneous effects, Markov equivalent graphs can at most differ by the direction of those effects. However, there are many cases where even that direction can be identified because different directions of instantaneous effects induce different sets of v-structures. A simple example is shown in Figure 10.5.
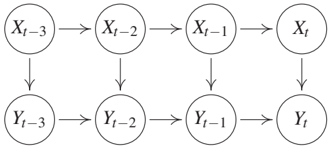
The direction of the instantaneous effect can still be inferred even if arrows from Xt to Y{t+1} for all t ∈ ℤ are added to Figure 10.5, and likewise if arrows from Yt to X{t+1} are added; we cannot add both, however, because this would remove all v-structures. The following sufficient condition for the identifiability of the direction of instantaneous effects has been given by Peters et al. [2013, Theorem 1]:
Theorem 10.2 (Identifiability for acyclic summary graphs) Assume that two full time graphs are induced by SCMs, and that in both cases for each j, X^jt is influenced by X^j{t-s} for some s ≥ 1. Assume further that the summary graphs are acyclic. If the full time graphs are Markov equivalent, then they are equal.
The following result shows that the presence of any arrow in the summary graph can in principle be decided from a single conditional independence test.
Theorem 10.3 (Justification of Granger causality) Consider an SCM without instantaneous effects for the time series (Xt){t∈ℤ} such that the induced joint distribution is faithful with respect to the corresponding full time graph. Then the summary graph has an arrow from X_j to X_k if and only if there exists a t ∈ ℤ such that
$$X^k_t \not\perp!!!\perp X^j_{past}(t) | X^{-j}_{past}(t).$$ (10.3)
For completeness, we have included the proof in Appendix C.14. Similar results can be found in White and Lu [2010] and Eichler [2011, 2012]. As already suggested by the headline of Theorem 10.3, this is the basis of Granger causality that we discuss in more detail in Section 10.3.3.
Some Causal Conclusions Do Not Require Faithfulness
Remarkably, interesting causal conclusions can even be made from conditional dependences without using faithfulness. This is in contrast to the i.i.d. case where any distribution is Markovian with respect to the complete DAG for any ordering of nodes. Since there are no arrows backward in time, the Markov condition for time series is sufficient to infer whether the summary graph is X → Y or Y → X, given that one of the two alternatives is true.
Theorem 10.4 (Detection of arrow X → Y) Consider an SCM for the bivariate time series (Xt, Y_t){t∈ℤ}.
(i) If there is a t ∈ ℤ such that
$$Y_t \not\perp!!!\perp X_{past}(t) | Y_{past}(t),$$ (10.4)
then the summary graph contains an arrow from X to Y.
(ii) Assume further that there are no instantaneous effects and the joint density of any finite subset of variables is strictly positive. If for all t ∈ ℤ, we have
$$Y_t \perp!!!\perp X_{past}(t) | Y_{past}(t),$$ (10.5)
then the summary graph contains no arrow from X to Y.
Again, this proof may have appeared elsewhere, but we include it for completeness in Appendix C.15. Proving (ii) requires causal minimality, which is strictly weaker than faithfulness.
In the next subsection we will see that Theorem 10.4 and various variations [e.g., White and Lu, 2010, Eichler, 2011, 2012] link conditional independence-based approaches to causal discovery to Granger causality.
Granger Causality
For simplicity, we start with the bivariate version of Granger causality.
Bivariate Granger Causality Theorem 10.4 shows (subject to excluding instantaneous effects together with mild technical conditions) that the presence or absence of an arrow in the summary graph can be inferred by testing (10.5) and the analogous statement when exchanging the roles of X and Y. We can then distinguish between the possible summary graphs X ⊥⊥ Y, X → Y, X ← Y, X ↔ Y.
One infers that X influences Y whenever the past values of X help in predicting Y from its own past. Formally, we write
$$X \text{ Granger-causes } Y :\Leftrightarrow Y_t \not\perp!!!\perp X_{past}(t) | Y_{past}(t).$$ (10.6)
This idea already goes back to Wiener [1956, pages 189-190], who argued that X has a causal influence on Y if the prediction of Y from its own past is improved by additionally accounting for X. The typical scenario, in which Theorem 10.4 holds is depicted in Figure 10.6.
Often Granger causality refers to linear prediction. Then, one compares the following two linear regression models:
$$Y_t = \sum_{i=1}^q a_i Y_{t-i} + N_t$$ (10.7)
$$Y_t = \sum_{i=1}^q a_i Y_{t-i} + \sum_{i=1}^q b_i X_{t-i} + \tilde{N}_t,$$ (10.8)
where (Nt){t∈ℤ} and (Ñt){t∈ℤ} are assumed to be i.i.d. time series, respectively. X is inferred to Granger-cause Y whenever the noise term Ñt (for predictions including X) has significantly smaller variance than the noise term N_t obtained without X. This amounts to saying that Y_t has non-vanishing partial correlations to X{past}(t), given Y_{past}(t). For multivariate Gaussian distributions, this is equivalent to the dependence statement (10.4). Modifications of this idea that use nonlinear regression have been extensively studied, too [e.g., Ancona et al., 2004, Marinazzo et al., 2008]. For non-parametric testing of (10.5) see, for instance, Diks and Panchenko [2006] and references therein.
An information theoretic quantity measuring the dependence between Y_t and the past of X, given the past of Y, is given by transfer entropy [Schreiber, 2000]:
$$TE_{X→Y} := I(Y_t : X_{past}(t) | Y_{past}(t)),$$ (10.9)
where I(A : B | C) denotes the conditional mutual information [Cover and Thomas, 1991] for any three sets A, B, C of variables; see also Appendix A. Estimating transfer entropy and inferring that X causes Y whenever it is significantly greater than 0 can thus be considered as an information theoretic implementation of Granger causality that accounts for arbitrary nonlinear influences. It is therefore tempting to consider transfer entropy as a measure of the strength of the influence of X on Y, but 'Limitations of Granger Causality' will explain why this is not appropriate.
Multivariate Granger Causality The assumption of causal sufficiency of a bivariate time series as in Theorem 10.4 is often inappropriate. This has already been addressed by Granger [1980]. We therefore say X_j Granger causes X_k if
$$X^k_t \not\perp!!!\perp X^j_{past}(t) | X^{-j}_{past}(t).$$
Granger already emphasized that proper use of Granger causality would actually require to condition on all relevant variables in the world. Nevertheless, Granger causality is often used in its bivariate version or in situations, in which clearly important variables are unobserved. Such a use can yield misleading statements when interpreting the results causally.
Limitations of Granger Causality Violation of causal sufficiency is—as in the i.i.d. scenario of the previous chapters—a serious issue in causal time series analysis. To explain why Granger causality is misleading in a causally insufficient multivariate time series, we restrict the attention to the case where only a bivariate time series (Xt, Y_t){t∈ℤ} is observed. Assume that both Xt and Y_t are influenced by previous instances of a hidden time series (Z_t){t∈ℤ}. This is depicted in Figure 10.7(a) where Z influences X with a delay of 1, and Y with a delay of 2. Assuming faithfulness, the d-separation criterion tells us
$$Y_t \not\perp!!!\perp X_{past}(t) | Y_{past}(t),$$ $$X_t \not\perp!!!\perp Y_{past}(t) | X_{past}(t).$$
while we have
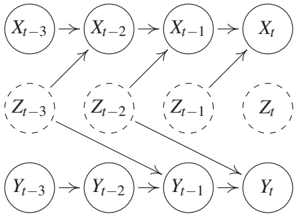
Thus, naive application of Granger causality infers that X causes Y and Y does not cause X. This effect has been observed, for instance, for the relation between the price of butter and the price of cheese. Both prices are strongly influenced by the price of milk, but the production of cheese takes much longer than the production of butter, which causes a larger delay between the prices of milk and cheese [Peters et al., 2013, Experiment 10]. This failure of Granger causality, however, is only possible because not all relevant variables are observed, which was stated as a requirement by Granger himself.
A second example for a scenario where Granger fails has been provided by Ay and Polani [2008] and is depicted in Figure 10.7(b). Assume that X*{t-1} influences Y_t deterministically via a copy operation, that is, Y_t := X*{t-1}. Likewise, the value of Y*{t-1} is copied to X_t. Then it is intuitively obvious that X and Y strongly influence each other in the sense that intervening on the value X_t changes all the values Y*{t+1+2k} for k ∈ ℕ₀. Likewise, intervening on Yt changes all values X{t+1+2k}. Nevertheless, the past of X is useless for predicting Y_t from its past, because Y_t can already be predicted perfectly from its own past. Certainly, deterministic relations are in general problematic for conditional independence-based causal inference since determinism induces additional independences. For instance, if Y is a function of X in the causal chain X → Y → Z, we get Y ⊥⊥ Z | X, which is not typical for this causal structure. One may therefore argue that this example is artificial and a more natural version would be a noisy copy operation. For the case where X_t and Y_t are binary variables, Janzing et al. [2013, Example 7] show that the transfer entropy converges to 0 when the noise level of the copy operation tends to 0. Then, Granger causality would indeed infer that X causes Y and Y causes X, but for small noise the tiny amount by which the past of X improves the prediction of Y_t does not properly account for the mutual influence between the time series (which is still strong in an intuitive sense). In this sense, transfer entropy is not an adequate measure for the strength of causal influence of one time series on another one. Janzing et al. [2013] discuss the limitations of different proposals to quantify causal influence (both for time series and the i.i.d. setting) and propose another information theoretic measure of causal strength. To summarize this paragraph, we emphasize that the qualitative statement about presence or absence of causal influence in the case of two causally sufficient time series only fails for a rather artificial scenario, while quantifying the causal influence via transfer entropy (which is suggested by interpreting 'improvement of prediction' in information theoretic terms) can be problematic also in less artificial scenarios.
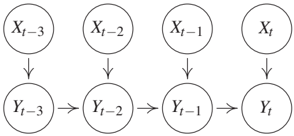
There is another scenario where Granger causality is quantitatively misleading but its qualitative statement remains correct unless faithfulness is violated (it uses, however, instantaneous effects, for which one may argue that they disappear for sufficiently fine time resolution [Granger, 1988]). For Figure 10.8(a), d-separation yields
$$Y_t \perp!!!\perp X_{past}(t) | Y_{past}(t).$$
Intuitively speaking, only the present value Xt would help for better predicting Y_t, but the past values X{t-1}, X*{t-2}, ... are useless and thus, Granger causality does not propose a link from X to Y. In Figure 10.8(b), however, Granger causality does detect the influence of X on Y (if we assume faithfulness) although it is still purely instantaneous, but the slight amount of improvement of the prediction does not properly account for the potentially strong influence of X_t on Y_t. To account for instantaneous effects, modifications of Granger causality have been proposed that add instantaneous terms in the corresponding SCM, but then identifiability may break down [e.g., Lütkepohl, 2007, (2.3.20) and (2.3.21)]. Knowing that a system contains instantaneous effects may suggest modifying Granger causality by regressing Y_t in (10.8) not only on X*{past}(t) but on Xt ∪ X{past}(t) instead. However, as already noted by Granger [1988], this may yield wrong conclusions: if X_t helps in predicting Y_t, this could equally well mean that Y_t influences X_t instead of indicating an influence from X_t to Y_t.
Remark 10.5 (Model misspecification may help) There is a paradoxical message of this insight: even in the case in which variables influence other variables instantaneously, for inferring causal statements it is more conclusive to check whether the past of a variable helps for the prediction rather than to check whether the past and the present value help. Condition (i) of Theorem 10.4 does not exclude instantaneous effects. Therefore (subject to causal sufficiency), we can still conclude that every benefit of X*{past}(t) for predicting Y_t from Y*{past}(t) is due to an influence of X on Y. Moreover, whenever there is any influence of X on Y, no matter whether it is purely instantaneous or not, X*{past}(t) will in the generic case improve our prediction of Y_t, given Y*{past}(t).
Models with Restricted Function Classes
To address the limitations of Granger causality, Hyvärinen et al. [2008] describe linear non-Gaussian autoregressive models that render causal structures with instantaneous effects identifiable. Peters et al. [2013] describe how to address this task using less restrictive function classes f_j in (10.1). One example is given by adapting ANMs to time series, that is, to use the SCM
$$X^j_t := f_j((PA^j_q){t-q}, \cdots, (PA^j_1){t-1}, (PA^j_0)_t) + N^j_t,$$
for j ∈ {1, ..., d}. Apart from identifiability of causal structures within Markov equivalence classes, there is a second motivation using restricted function classes: using simulated time series, Peters et al. [2013] provide some empirical evidence for the belief that time series that admit models from a restricted function class are less likely to be confounded.
Spectral Independence Criterion
The spectral independence criterion (SIC) is a method that is based on the idea of independence between cause and mechanism described in Shajarisales et al. [2015]. Assume we are given a weakly stationary bivariate time series (Xt, Y_t){t∈ℤ} where either X influences Y or Y influences X via a linear time invariant filter. More explicitly, for the case that X influences Y, Y is then obtained from X by convolution with a function h:
$$Y_t = \sum_{k=1}^{\infty} h(k) X_{t-k}.$$ (10.10)
For technical details, such as the decay conditions for h that ensure that (10.10) and expressions below are well-defined, we refer to Shajarisales et al. [2015]. To formalize an independence condition between X and h, we consider the action of the filter in the frequency domain: for all ν ∈ [-1/2, 1/2], let S_{XX}(ν) denote the power spectral density for the frequency ν; the latter is explicitly given by the Fourier transform of the auto-covariance function
$$C_{XX}(τ) := E[X_t X_{t+τ}], \text{ with } τ ∈ ℤ.$$
Then, (10.10) yields
$$S_{YY}(ν) = |\tilde{h}(ν)|^2 \cdot S_{XX}(ν),$$ (10.11)
where $\tilde{h}(ν) = \sum_{k∈ℤ} e^{-i2πνk} h(k)$ denotes the Fourier transform of h. In other words, multiplying the power spectrum of the input time series with the squared transfer function of the filter yields the power spectrum of the output. Whenever $\tilde{h}$ is invertible, in addition to (10.11) we have
$$S_{XX}(ν) = \left|\frac{1}{\tilde{h}(ν)}\right|^2 \cdot S_{YY}(ν).$$ (10.12)
While both equations (10.11) and (10.12) are valid, the question is which one describes the causal model. The idea is that for the causal direction, the power spectrum of the input time series carries no information about the transfer function of the filter. To formalize this, Shajarisales et al. [2015] state the following independence condition:
Definition 10.6 (SIC) The time series X and the filter h are said to satisfy the SIC if S_{XX} and $|\tilde{h}|^2$ are uncorrelated, that is,
$$\langle S_{XX} \cdot |\tilde{h}|^2 \rangle = \langle S_{XX} \rangle \cdot \langle |\tilde{h}|^2 \rangle,$$ (10.13)
where $\langle f \rangle := \int_{-1/2}^{1/2} f(ν) dν$ denote the average of any function on the frequency interval [-1/2, 1/2].
Shajarisales et al. [2015] show that (10.13) implies that the analogue independence condition for the backward direction does not hold, except for the non-generic case where $|\tilde{h}|$ is constant over the whole interval of frequencies.
Theorem 10.7 (Identifiability via SIC) If (10.13) holds and $|\tilde{h}|$ is not constant in ν then S_{YY} is negatively correlated with 1/|$\tilde{h}$|², that is,
$$\langle S_{YY} \cdot 1/|\tilde{h}|^2 \rangle < \langle S_{YY} \rangle \cdot \langle 1/|\tilde{h}|^2 \rangle.$$ (10.14)
Proof. The left-hand sides of (10.13) and (10.14) are given by $\langle S_{YY} \rangle$ and $\langle S_{XX} \rangle$, respectively. Jensen's inequality states 1/$\langle |\tilde{h}|^2 \rangle$ < $\langle 1/|\tilde{h}|^2 \rangle$, which implies the statement. ∎
Shajarisales et al. [2015] propose a simple causal inference algorithm that checks which direction is closer to satisfying SIC. They report some encouraging results using SIC for experiments with various simulated and real-world data sets.
Dynamic Causal Modeling
Dynamic causal modeling (DCM) is a technique that has been developed particularly for inferring causal relations between the activities of different brain regions [Friston et al., 2003]. If the vector z ∈ ℝⁿ encodes the activity of n brain regions and u ∈ ℝᵐ a vector of perturbations, the dynamics of z is given by a differential equation of the form
$$\frac{d}{dt}z = F(z, u, θ),$$ (10.15)
where F is a known function, u ∈ ℝᵐ is a vector of external stimulations, and θ parametrizes the model class describing the causal links between the different brain regions. One often considers the following bilinear approximation of (10.15):
$$\frac{d}{dt}z = \left(A + \sum_{j=1}^m u_j B_j\right) z + Cu,$$ (10.16)
where A, B₁, ..., Bₘ are n × n matrices and C has the size n × m. While A describes the mutual influence of the activities z_j in different regions, the matrices B_j describe how u changes their mutual influence. C encodes the direct influence of u on z.
Here, z is not directly observable, but one can detect the hemodynamic response. The blood flow provides an increased amount of nutrients (such as oxygen and glucose) to compensate for the increased demand of energy. Functional magnetic resonance imaging (fMRI) is able to detect this increase via the blood-oxygen-level-dependent (BOLD) signal. Defining a state vector x that includes both the brain activity and some hemodynamic state variables, one ends up with a differential equation for x
$$\frac{d}{dt}x = f(x, u, θ)$$ (10.17)
by combining (10.16) with a dynamical model of the hemodynamic response. The high-dimensional parameter θ consists of all free parameters of (10.16) and parameters from modeling the hemodynamic response. Then, one uses a model of how x determines the measured BOLD signal y:
$$y = ℓ(x).$$ (10.18)
Finally, as data, we obtain an observed time series of y-vectors. DCM then infers the matrices in (10.16) from these data using various known techniques for learning models with latent variables, for example, expectation maximization (EM).
Lohmann et al. [2012a] criticize DCM mainly because the number of model parameters explodes with growing n and m, which renders their identification impossible from empirical data. According to their experiments with simulated brain connections, a large fraction of wrong models obtained higher evidence by DCM than the true model. These findings triggered a debate about DCM; see also Friston et al. [2013] for a response to Lohmann et al. [2012a] and Lohmann et al. [2012b] for a response to Friston et al. [2013].
Problems
Problem 10.8 (Acyclic summary graphs) Prove Theorem 10.2.
Problem 10.9 (Instantaneous effects) Consider an SCM over a multivariate time series, in which each variable X^j_t is influenced by all past values of all components X^k. Additionally, assume that the instantaneous effects form a DAG and that the distribution is Markovian and faithful with respect to the full time graph. To which extent can one identify the instantaneous DAG structure from the distribution?
Problem 10.10 (Granger causality) Argue why Granger causality results in 'X G-causes Y' and 'Y G-causes X' if one adds arrows Zt → Z{t+1} for t ∈ ℤ in Figure 10.7(a).